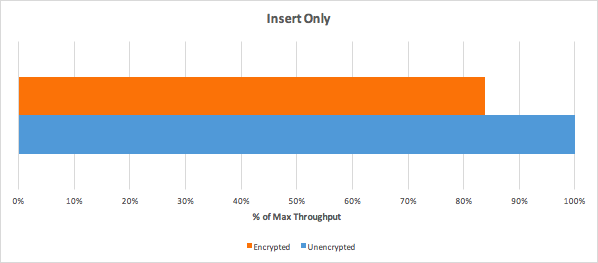
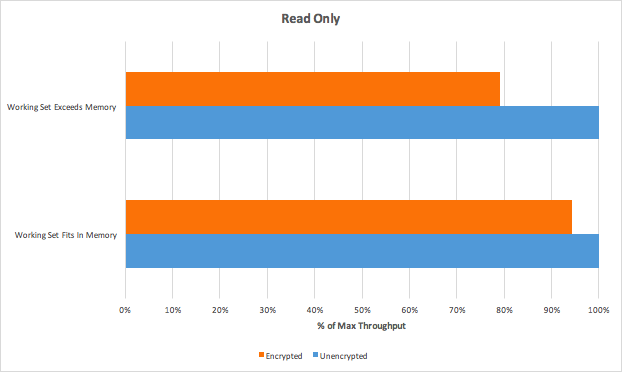
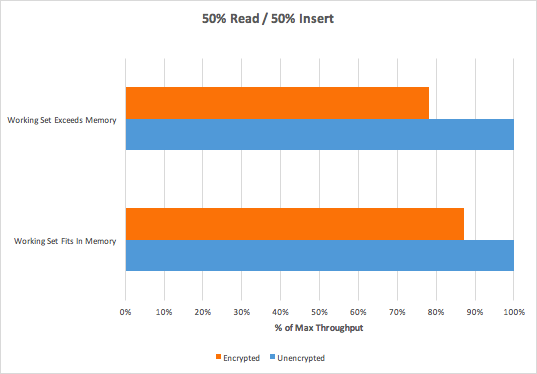
The main goal of this document is to describe the most commonly used commands of the aggregation pipeline and also give some recommendations for aggregation requests implementation. There will be also a sample solution for C# environment at the end of the document.
Quick Reference
$match
Filters the documents to pass only the documents that match the specified condition(s) to the next pipeline stage.
{ $match: { <query> } }
$project
Passes along the documents with the requested fields to the next stage in the pipeline. The specified fields can be existing fields from the input documents or newly computed fields.
{ $project: { <specification(s)> } }
Specifications can be the following:
<field>: <1or true> | Specifies the inclusion of a field. |
_id: <0 orfalse> | Specifies the suppression of the _id field. |
<field>:<expression> | Adds a new field or resets the value of an existing field. |
<field>:<0or false> |
Specifies the exclusion of a field.
|
$sort
Sorts all input documents and returns them to the pipeline in sorted order.
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
Sort order can be the following values:
1 to specify ascending order.-1 to specify descending order.
$lookup
Performs a left outer join to an unsharded collection in the same database to filter in documents from the “joined” collection for processing. To each input document, the $lookup stage adds a new array field whose elements are the matching documents from the “joined” collection. The $lookup stage passes these reshaped documents to the next stage.
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
Aggregation Pipeline Optimization
All optimizations here have their target to minimize the amount of data that are sent between pipeline stages. Also, these optimizations are done automatically by MongoDB engine, but it will probably be the right decision to eliminate at least partly the need for such optimizations to make DB engine work a bit faster.
All optimizations are done in two phases: sequence optimization and coalescence optimization. As a result, long chains of aggregation phases sometimes can be transformed into a lesser number of phases that require less memory.
Pipeline Sequence Optimization
$project or $addFields + $match
If $match follows $project or $addFields, then that expressions from match stage that doesn't need to be computed in projection stage are moved before projection stage.
$sort + $match
In this case $match is moved before $sort to minimize number of items to sort.
$redact + $match
If $redact stays before $match, then sometimes we can add portion of $match statement before $redact to limit number of documents aggregated.
$skip + $limit
During optimization $limit is moved before $skip, and the $limit value is increased by $skip amount.
$project + $skip or $limit
Obviously, in this case $skip or $limit goes before $project to limit number of documents to be projected.
Pipeline Coalescence Optimization
When possible, the optimization phase coalesces a pipeline stage into its predecessor. Generally, coalescence occurs after any sequence reordering optimization.
$sort + $limit
When a $sort immediately precedes a $limit, the optimizer can coalesce the $limit into the $sort. This allows the sort operation to only maintain the top n results as it progresses, where n is the specified limit, and MongoDB only needs to store n items in memory.
$limit + $limit
When a $limit immediately follows another $limit, the two stages can coalesce into a single $limit where the limit amount is the smaller of the two initial limit amounts.
$skip + $skip
When $skip immediately follows another $skip, the two stages can coalesce into a single $skip where the skip amount is the sum of the two initial skip amounts.
$match + $match
When a $match immediately follows another $match, the two stages can coalesce into a single $match combining the conditions with an $and.
$lookup + $unwind
When a $unwind immediately follows another $lookup, and the $unwind operates on the as a field of the $lookup, the optimizer can coalesce the $unwind into the $lookup stage. This avoids creating large intermediate documents.
Aggregation Pipeline Limits
Each document in the result set is limited by the maximum size of BSON Document, it's currently 16 megabytes. If any single document exceeds this limit, the 'aggregate' command will produce an error. The limit only applies to the returned documents; during the pipeline processing, the documents may exceed this size.
Pipeline stages have a limit of 100 megabytes of RAM. If a stage exceeds this limit, MongoDB will produce an error. To allow for the handling of large datasets, use the allowDiskUse option to enable aggregation pipeline stages to write data to temporary files.
The $graphLookup stage must stay within the 100 megabyte memory limit. If allowDiskUse: true is specified for the aggregate operation, the $graphLookup stage ignores the option. If there are other stages in the aggregate operation, allowDiskUse: true option will affect these other stages.
Aggregation Pipeline and Sharded Collections
The aggregation pipeline supports operations on sharded collections.
Behavior
If the pipeline starts with an exact $match on a shared key, the entire pipeline runs on the matching shard only. Previously, the pipeline would have been split, and the work of merging it would have to be done on the primary shard.
For aggregation operations that must run on multiple shards, if the operations do not require running on the database’s primary shard, these operations will route the results to a random shard to merge the results to avoid overloading the primary shard for that database. The $out stage and the $lookup stage require running on the database’s primary shard.
Optimization
When splitting the aggregation pipeline into two parts, the pipeline is split to ensure that the shards perform as many stages as possible with consideration for optimization.
To see how the pipeline was split, include the explain option in the db.collection.aggregate() method.
Optimizations are subject to change between releases.
Time measure experiment
For this experiment I used following data:
100 000 records for Users
100 000 records for Items
1 000 000 records for Orders, that contain user id and can contain up to 10 items ids.
Experiment was done with four tests: simple match, match using collection 'contains' function, lookup with match, and lookup & match & unwind & group.
Also time has been measured for following cases: when foreign key was object id with ascending index and hash index, and when foreign key was GUID with ascending index and hash index.
I've got following results:
| simple match | 0.168s | 0.168s | 0.171s | 0.18s | 0.183s | 0.179s | 0.185s | 0.183s | 0.194s | 0.177s |
|---|
| match with 'contains' | 0.709s | 0.722s | 0.814s | 0.83s | 0.793s | 0.828s | 0.798s | 0.787s | 0.79s | 0.781s |
|---|
| lookup & match | 66.373s | 79.796s | 79.823s | 97.733s | 83.317s | 97.171s | 85.767s | 98.76s | 42501.798s ≈ 11h 48m 21.798s | 83.502s |
|---|
| lookup & unwind & match & unwind & group | 75.856s | 74.563s | 81.012s | 86.546s | 84.847s | 86.375s | 86.045s | 85.928s | 44605.215s ≈ 12h 23m 25.215s | 82.692s |
|---|
| lookup & unwind & match & unwind & lookup & unwind & group | 73.797s | 74.129s | 83.504s | 87.338s | 85.418s | 86.321s | 86.303s | 86.572s | 44763.693s ≈ 12h 26m 03.693s | 82.749s |
|---|
Results are pretty bad, as we can see. But, there is a way to do it right!
This measurements were done by using aggregation pipeline on Orders, that was lookup-ed with Users and filtered on username AFTER that. But what if we use aggregation pipeline on Users, filter it on username and do a lookup with Orders collection. The results I've got are following:
| simple match | 0.187s |
|---|
| match with 'contains' | 0.807s |
|---|
| lookup & match | 0.062s |
|---|
| lookup & unwind & match & unwind & group | 0.038s |
|---|
| lookup & unwind & match & unwind & lookup & unwind & group | 0.014s |
|---|
So, as we can see, now we have a very good request speed with aggregation pipeline. So, we should think very carefully about optimizations while using the aggregation pipeline.
Also I did tests on the same tasks but without aggregation pipeline usage. The results are following:
| simple match | 0.008s |
|---|
| match with 'contains' | 0.012s |
|---|
| lookup & match | 0.566s |
|---|
| lookup & unwind & match & unwind & group | 0.652s |
|---|
| lookup & unwind & match & unwind & lookup & unwind & group | 0.838s |
|---|
Of course, these tests were done without such things as indexes, etc. That's why they are executed for a bit longer.