Intro
At the beginning of our developing on one of my projects we planned that we will use Azure CosmosDB for Mongo database hosting. Mainly we chose Cosmos because it is easy to set up, good features like autoscaling, autoindexing, SLA, and we can work with it as with black box without any big expertise in that technology. But during the development process, we have found some disadvantages for us. Two main limitations for us:
- CosmosDB does not support API version of MongoDB greater than 3.4. We could not use many important Mongo features like transactions, schema validations etc.
- There is no normal CosmosDB emulator for local dev environment.
Description
MongoDB Atlas is a fully-managed cloud database developed by the same people that build MongoDB. Atlas handles all the complexity of deploying, managing, and healing your deployments on the cloud service provider of your choice (AWS, Azure, and GCP). Follow the links below to get started.
Main advantages and disadvantages
Fully MongoDB API version support
We confidently can work with a local MongoDB database on dev environments.
We should choose between sharded cluster and replica set. Also, we should deal with Global Clusters and Global Write Zones and Zone Mapping.
Anyway, we should have more expertise in MongoDB.
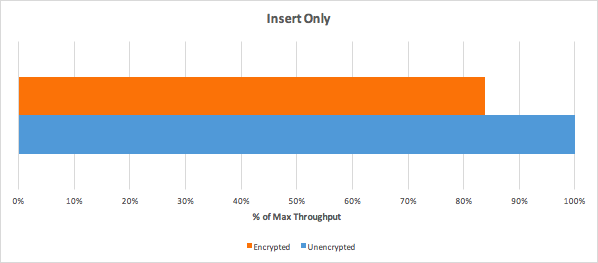
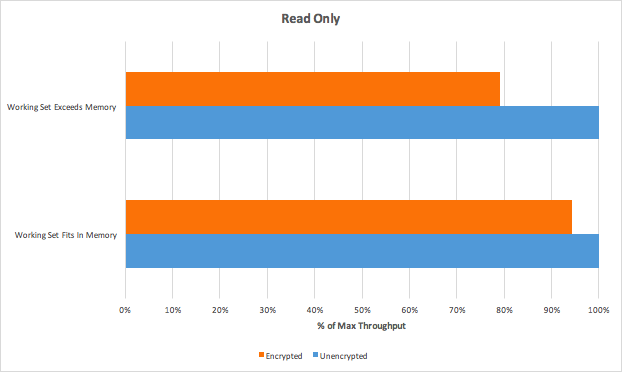
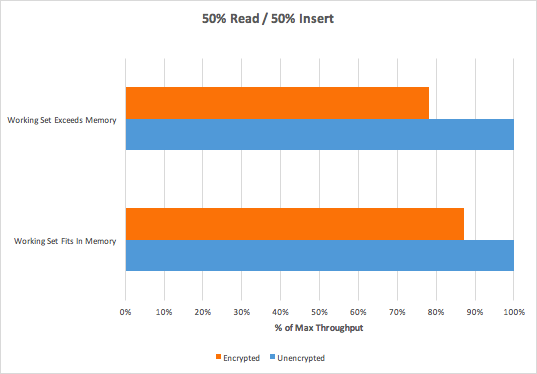
Comparison with CosmosDB
from https://www.percona.com/live/e17/sessions/mongodb-shootout-mongodb-atlas-azure-cosmosdb-and-doing-it-yourself :
Additional features

Additional features
MongoDB Connector for BI
The MongoDB Connector for Business Intelligence (BI) allows users to create queries with SQL and visualize, graph, and report on their MongoDB Enterprise data using existing relational business intelligence tools such as Tableau, MicroStrategy, and Qlik.
The MongoDB Connector for BI acts as a layer that translates queries and data between a mongod ormongos instance and your reporting tool. The BI Connector stores no data, and purely serves to bridge your MongoDB cluster with business intelligence tools.

User Authentication and Authorization with LDAP - Connect to your clusters via LDAP / Active Directory
Connect via BI Connector for Atlas
Database Auditing - Audit activity on your database
MongoDB Stitch - Create a serverless application
MongoDB Charts¶ - Visualize data in MongoDB
Cluster Tier selection
Select your preferred cluster instance size. The selected instance size dictates the memory, storage, and IOPS specification for each data-bearing server [1] in the cluster.
Atlas categorizes the instance sizes into tiers as follows:
Shared Clusters
Sandbox replica set clusters for getting started with MongoDB. These instances deploy to a shared environment with access to a subset of Atlas features and functionality. For complete documentation on shared cluster limits and restrictions, see Atlas M0 (Free Tier), M2, and M5 Limitations.
Dedicated Development Clusters
Instances that support development environments and low-traffic applications.
These instances support replica set deployments only, but otherwise, provide full access to Atlas features and functionality.
Dedicated Production Clusters
Instances that support production environments with high traffic applications and large datasets.
These instances support replica set and sharded cluster deployments with full access to Atlas features and functionality.
The following table highlights key differences between an
M0 Free Tier cluster, an M2 or M5 shared starter cluster, and an M10+ dedicated cluster.
Atlas M0 (Free Tier), M2, and M5 Limitations
Maximum of 100 operations per second allowed for
M0 Free Tier and M2/M5 shared clusters.M0 Free Tier and M2/M5 shared clusters are allowed a maximum of 100 connections.M0/M2/M5 clusters limit the total data transferred into or out of the cluster as follows:M0: 10 GB per weekM2: 20 GB per weekM5: 50 GB per week
Atlas throttles the network speed of clusters which exceed the posted limits.
M0 Free Tier and M2/M5 shared clusters have a maximum of 100 databases and 500 collections total.Global Clusters
Atlas Global Clusters uses a highly curated implementation of sharded cluster zones to support location-aware read and write operations for globally distributed application instances and clients. Global Clusters support deployment patterns such as:
- Low-latency read and write operations for globally distributed clients.
- Uptime protection during partial or full regional outages.
- Location-aware data storage in specific geographic regions.
How does MongoDB Atlas deliver high availability?
Billing
Deploying clusters onto Microsoft Azure
Links
All MongoDB docs: https://docs.mongodb.com/
Atlas docs: https://docs.atlas.mongodb.com/
MongoDB Connector for BI docs: https://docs.mongodb.com/bi-connector/current/
https://www.mongodb.com/cloud/atlas/azure-mongodb?utm_campaign=Int_EM_MDBE18_Release_announcement_11_18_EMEA&utm_medium=email&utm_source=Eloqua
https://azure.microsoft.com/en-us/blog/microsoft-azure-tutorial-how-to-integrate-azure-functions-with-mongodb/
https://www.mongodb.com/cloud/atlas/pricing
https://www.percona.com/live/e17/sessions/mongodb-shootout-mongodb-atlas-azure-cosmosdb-and-doing-it-yourself
https://azure.microsoft.com/en-us/blog/microsoft-azure-tutorial-how-to-integrate-azure-functions-with-mongodb/
https://www.mongodb.com/cloud/atlas/pricing
https://www.percona.com/live/e17/sessions/mongodb-shootout-mongodb-atlas-azure-cosmosdb-and-doing-it-yourself